Starting the Crawler
The quality of your search results depends on the quality of your search index. This is why it is crucial to tell the Site Search 360 crawler which pages, documents, and other content on your site is important for your visitors.
In case you have never heard of a crawler before, it is a type of bot that browses your website and builds the search index that your search is based on. A search index is a list of pages and documents that are shown as search results in response to a query that your site visitor types into a search box on your site.
You have two main options to direct our crawler to the right pages and content:
1. Website Crawling
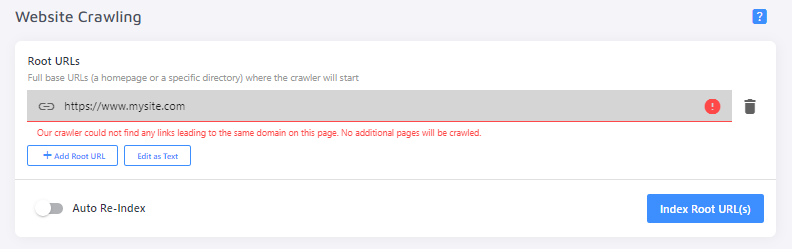
When you enter a root URL (typically your homepage) and click Index, our crawler will visit the root URL and follow all the links it finds that point to other pages on your site. The pages it finds will be added to your index.
You can enter just one root URL or several.
2. Sitemap Indexing
Sitemap Indexing is our preferred indexing method as it is the quickest and most efficient way to crawl a website.
If we can detect a valid sitemap XML file for the domain you've provided at registration, our crawler will go to that sitemap—typically found at https://www.yoursite.com/sitemap.xml or https://www.yoursite.com/sitemap-index.xml—to pick up your website URLs listed there.
Note: The sitemap XML file must be formatted correctly for the crawler to process it. Check out these guidelines.
If we cannot detect a valid sitemap for your domain, we automatically switch on the Website Crawling method.
If we did not detect your sitemap, but you have one, simply provide the URL to your sitemap (or sitemaps, if you have more than one). Press Test Sitemap to make sure your sitemap is valid and ready for indexing. This check also shows you how many URLs are found in your sitemap. If that works, you can go ahead and press Index All Sitemaps.


Note: with Website Crawling, the only way to check the number of indexed pages and documents is to wait until a full crawl is complete.
If necessary, you can use Website Crawling and Sitemap Indexing at the same time.
Don't forget to switch on the "Auto Re-Index" toggle under the preferred crawling method(s)!
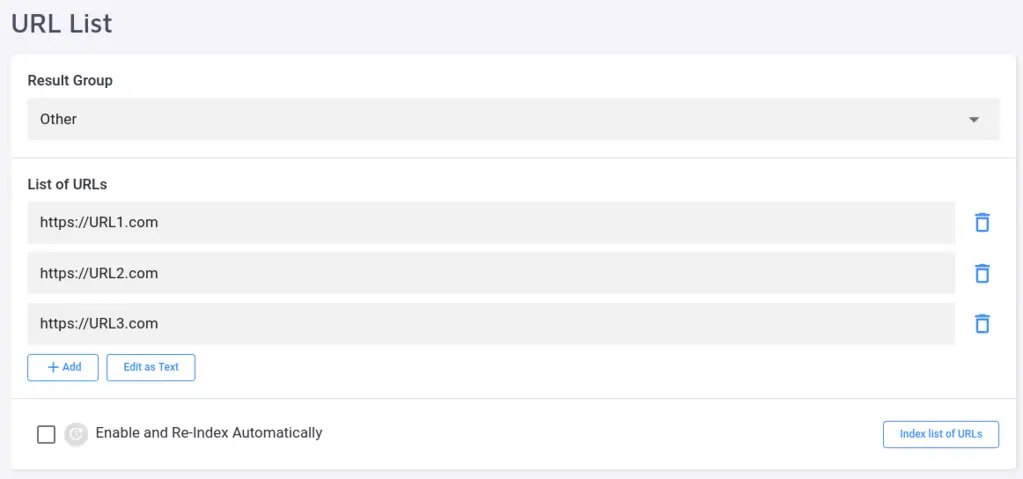
3. URL List
For one reason or another, our crawler may fail to pick up some URLs, or you might just need to index a small number of specific pages. In this case, we have a third crawling option: the URL list. With this feature, you can add pages to the index manually.
This method is different from adding URLs one by one under Index:
The URL List isn't purged upon a full re-index, whereas links added manually under the Index section are deleted from the index.
The URL list allows you to add links in bulk by clicking "Edit as Text", instead of copying and pasting them individually.
How do I index and search over multiple sites?
Let's assume you have the following setup:
A blog under http://blog.mysite.com/
Your main page under http://mysite.com/
And some content on a separate domain http://myothersite.com/
Now you want to crawl all three sites and end up with one index and a search that finds content on all those pages.
This can be easily achieved by using one or a combination of the following three methods:
Create a sitemap that contains URLs from all the sites you want to index or submit multiple sitemaps, one per line. In this case, our crawler only picks up the links that are present in your sitemap(s).
Let the crawler index multiple sites by providing multiple root URLs in Website Crawling.
Add pages from any of your sites via the API using your API key (available for Holmes plan or higher). You can either index by URL or send a JSON object with the indexable content.
Tip: consider setting up Result Groups to segment results from different sites or site sections. By default, result groups will be shown as tabs.
Now you are familiar with the main ways to start the crawler and build your search index. For information on how to further control which pages end up in your index from your configured sources, refer to our Crawler Settings.